 pyaar harmonize
pyaar harmonize
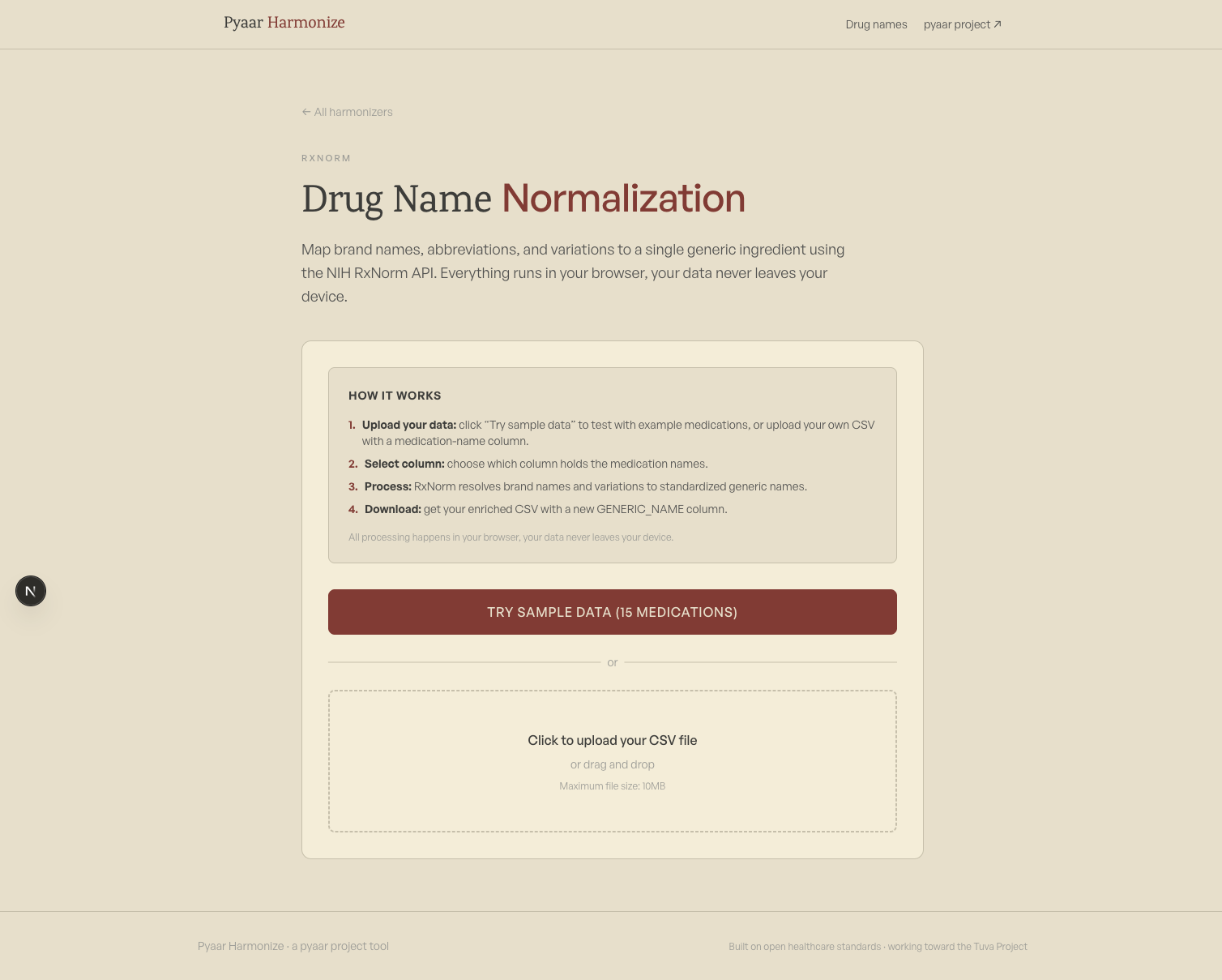
pyaar harmonize turns messy healthcare data into analytics-ready data, a growing suite of vocabulary and data-quality harmonizers aligned with the open-source Tuva Project. The first tool, drug-name normalization, maps brand names, abbreviations, and misspellings to standardized RxNorm generic names, collapsing hours of manual medication mapping into a two-minute, privacy-first (in-browser) process.

pyaar harmonize
Turn messy healthcare data into analytics-ready data.
pyaar harmonize is a growing suite of harmonizers that standardize the vocabularies healthcare data is built on, RxNorm, ICD-10, CPT, HCPCS, LOINC, SNOMED, and more. Each one is a small, browser-first tool that takes a messy input and hands back clean, standardized data.
It is built to align with the open-source Tuva Project, which turns raw claims and clinical data into a common data model through data quality, vocabulary normalization, and analytics-ready data marts. pyaar harmonize builds the same normalization primitives as focused, self-serve tools. The goal: to become a trusted partner in the Tuva ecosystem.
Live: harmonize.pyaarproject.org · Source: github.com/prahlaadr/pyaar-harmonize
The suite
| Harmonizer | Standard | Status |
|---|---|---|
| Drug Name Normalization | RxNorm | Live |
| NDC Crosswalk | NDC → RxNorm | Coming soon |
| Diagnosis Normalization | ICD-10-CM | Coming soon |
| Procedure Codes | CPT · HCPCS | Coming soon |
| Lab Harmonization | LOINC | Coming soon |
| Clinical Terms | SNOMED CT | Coming soon |
| Provider Identity | NPI · Taxonomy | Coming soon |
| Data Quality Checks | Tuva-style | Coming soon |
Each tile maps to a piece of the Tuva pipeline: raw data → data quality → vocabulary normalization → core data model → data marts. pyaar harmonize starts where the mess usually does, in vocabulary normalization, and starts with drugs.
First harmonizer: drug-name normalization
If you have ever worked with healthcare data from multiple sources, you know the pain. Hospital A calls it "Tylenol 500mg". Hospital B uses "acetaminophen 500 mg tablet". Hospital C logs it as "APAP 325mg". The pharmacy system says "Paracetamol".
They are all the same drug. But try telling that to your analytics pipeline.
This is a problem I saw firsthand at TargetRWE working with clinical data normalization. Data engineers would spend 2-4 hours manually mapping medication names before they could even start their analysis. This tool automates that.
The problem
Hospital A: "Tylenol 500mg"
Hospital B: "acetaminophen 500 mg tablet"
Hospital C: "APAP 325mg"
Pharmacy: "Paracetamol"Without normalization: your analysis treats these as four different drugs. With normalization: they all map to "acetaminophen", so accurate aggregation becomes possible. Multi-site clinical trials, insurance claims analysis, and drug-safety surveillance all need clean, standardized medication data.
The solution
Upload a CSV → select the medication column → get a new CSV with a GENERIC_NAME column added. The tool uses the NIH's public RxNorm API, the same database that powers most healthcare terminology services.
Privacy-first by design
Every API call happens in your browser. Your data never touches a server, which matters for HIPAA-sensitive data. RxNorm has CORS enabled, so browser-to-API calls work directly, no backend, no data upload, no timeouts.
Results
Stress-tested with 120 diverse medication name variations:
- Success rate: 85.8% (103/120 normalized)
- Processing time: ~2 minutes for 120 drugs
- Brand → generic: Tylenol → acetaminophen, Lipitor → atorvastatin, Ozempic → semaglutide
- Abbreviations: APAP → acetaminophen, HCTZ → hydrochlorothiazide
- Even misspellings: Ambian → zolpidem (fuzzy matching)
Remaining NOT_FOUND cases are mostly formulation or OTC-suffix edge cases (e.g. "Ventolin HFA", "Prilosec OTC"), which are RxNorm database limitations rather than tool bugs.
Tech
Next.js 15 (App Router) · TypeScript · TailwindCSS · PapaParse · RxNorm REST API · Vercel. The RxNorm client has exponential-backoff retry logic and AbortController timeouts; the CSV processor validates file size and type and auto-detects the medication column.
Why this matters
Partly it solves a real problem in healthcare data workflows. Partly it is a proof of direction: the same normalization primitives Tuva ships in a data warehouse, delivered as focused, privacy-first tools anyone can use in a browser, and built to plug into the Tuva ecosystem as a trusted partner.
What's next
The next harmonizers, NDC, ICD-10, CPT/HCPCS, LOINC, SNOMED, provider identity, and Tuva-style data-quality checks, extend the same pattern across the vocabularies healthcare data depends on.
Built at the intersection of healthcare data and product thinking.